John Gallagher, University of Illinois at Urbana-Champaign
Published April 4, 2017
Interactive templates dominate user experiences on the Internet. Users ranging from expert programmers to moderate technophobes predictably and repeatedly fill in the fields of Twitter, Facebook, and Instagram. When starting a new website, we can easily turn to a variety of predetermined formats (e.g, WordPress, Squarespace). Whereas early 1990s Internet technologies focused on individuals’ abilities to code homepages, the users of today’s interactive and participatory Internet (IPI) “…post within preformatted templates designed by the [website’s] creators” (Arola 5-6). This shift has led to a rhetorically overlooked aspect of Internet transactions: companies use these templates as interfaces to connect with their clients, leverage those clients into other clients, and target products to buyers. In other words, through Web 2.0 templates, users receive access to Internet spaces in exchange for the monetization of their activity. Users become the products of multinational Internet corporations, and templates structure that transition. Because this templated user experience dominates writing and rhetorical experiences online by literally structuring it, digital rhetoricians can play a key role in developing rhetorical practices that unearth and challenge the information-mining processes around templates.
In this essay, I describe one of these practices: a rhetorical practice of active data production. By active data production, I mean strategically filling in Web 2.0 templates with persuasive information that understands user information as a form of labor. In this sense, I argue for filling in templates with information that is not necessarily true (e.g., filling in an incorrect birthdate, updating a status that may not be a full truth, or strategically using hashtags and retweets). A rhetorical practice of active data production develops ways to challenge and work with this structured collection and monetization of our online activity. These persuasive interactions with data collection processes—what we might think of as rhetorical monetary transactions—ought to be understood as important rhetorical situations. The audiences of templates, after all, are companies’ information databases, which can be impacted by our input choices.[1] By seeing Web 2.0 templates as critical facilitators between users and website companies and being more conscious of how active data production leads to monetization, we can better identify and influence the economic implications of our interactions in online environments. As I will ultimately demonstrate, a rhetorical practice of active (and inactive) data production develops useful strategies for rhetorical agency in Web 2.0.
Web 2.0 as a Mediator of Monetized Transactions
To frame my discussion of Web 2.0, I first need to establish a distinction between what I called IPI and Web 2.0. Web 2.0 templates are subsets of IPI templates. IPI templates are not necessarily about monetization but about websites that offer interactions. Web 2.0 is a designation for websites that monetize this interactivity. In using Web 2.0 as a subcategory of IPI, I intentionally foreground the monetized exchanges of IPI templates when they are filled in repeatedly.[2] I draw this distinction because “Web 2.0” is a nebulous term—one so problematic that First Monday, a peer-reviewed journal about the Internet, dedicated the entire March 2008 issue to exploring the term. “Web 2.0” was introduced as an economic and marketing term attributed to Tim O’Reilly (2005) to capture the ways that businesses can monetize interactive websites because of developments in software and programming languages.[3] As Steve Holmes notes in “Rhetorical Allegorithms in Bitcoin,” “Companies extract labor value—pure information—from the traces of our networked practices such as browsing for books on Amazon.com, posting on a social media interface, or using a search engine for research.” The “pure information” that Holmes references is organized and recorded by IPI templates which, as interfaces, connect users and databases. These templates enable the collection and stockpiling of user information. For the purposes of this article, IPI templates become Web 2.0 templates when they become monetized (or when companies seek monetization of their websites).
Although he never explicitly mentions templates, Holmes’s argument is located on one end of the conversation about Web 2.0 templates: algorithms harvest and evaluate the user input generated from Web 2.0 templates, among a variety of other information.[4] The other aspect of this labor-value conversation is that these templates assemble and arrange the way that users input information, which allows for this transformation into commodities. To date, however, investigations on the user-end of templates tend to focus on the concept of design. Both Kristin Arola’s “The Design of Web 2.0: The Rise of the Template, The Fall of Design” and my own “The Rhetorical Template” focus explicitly on Web 2.0 templates with respect to design; but in doing so, we overlook the economic role these frameworks play in Internet economies and online economic exchanges.
When viewed from a monetary perspective, templates play an important role in creating economic value for a company. For instance, a key design feature of Web 2.0 templates is that they encourage constant and consistent use—such as Twitter’s layout, which always asks users to send a tweet by continually supplying an empty field to fill with content. Even private online forums engaged in ongoing democratic debate can be bought and sold when those forums are built around corporatized Web 2.0 templates that record user input. Online businesses can make money through this data in many ways, including selling the information to advertisers to allow user targeting and providing information about average user behaviors and trends for market research. Focusing on company-to-user interactions of Web 2.0 templates foregrounds an economic perspective of social media and other IPI environments. To have some control in these economies, we need to probe in detail how we fill in such templates.
Characteristics of Web 2.0 Templates
Templates supply choices about a body of images, alphabetic text, and rhetorical discourse to provide a sense of stability to our composing practices and processes. Templates in this broad sense are patterns or maps designed to help users produce rhetorical discourse. From a narrower point of view, Web 2.0 templates function as interfaces that guide how users write (and think[5]) within such environments. Designers of Web 2.0 templates aim for smooth and sleek designs to make moments of discontinuity fade—thus ensuring faster moments of communication with fewer moments of miscommunication. More communication results in more information, which, in turn, leads to more money. Situating templates as interfaces denaturalizes Web 2.0 design and makes them objects of inquiry.
Many of us do not pay critical attention to such interfaces, which is often the aim of designers. In Interface, Branden Hookway articulates an experience that most Internet designers desire: although an interface is an obstacle for users at first, it recedes into the background and instead helps users communicate. He notes that when users first experience interfaces, they tend to encounter them as a “form of separation, as a thing that challenges…” (123). However, after this initial user frustration fades, interfaces become “form[s] of augmentation” (123). With their computer code hidden, Web 2.0 templates thus appear to users as objects that facilitate easy and fast communication; they are rhetorical of course, but it’s easy to miss their profound influences since we often look through them rather than at them.
Categorizing Web 2.0 templates as interfaces can help draw critical attention to the way these templates influence communication and rhetorical discourse. Yet we must also understand the characteristics of Web 2.0 templates to denaturalize these interfaces and better understand how they influence communication expectations and writing practices. We especially need to understand that templates provide a specific range of alphabetic means, present a standard visual layout, and regulate community practices; their rhetorics are coercive in this sense.[6] Rhetorics that can be produced with(in) Web 2.0 templates, however, are still largely up to writers in that writers have a choice in how to fill these templates in a way they deem suitable. This rhetoric emerges from the interplay of a template’s affordances and a user’s aims. To take control of our own rhetorical interactions with templates, we need to identify the characteristics of Web 2.0 templates that encourage users to produce certain kinds of information and how these characteristics enable monetization. I identify three characteristics here: (a) repeatability, (b) time-space compression, and (c) standardization of information collection. Becoming aware of these characteristics is particularly necessary for understanding the role that users play in providing companies with monetizable information.
Repeatability
Web 2.0 templates are not single-use templates waiting to be filled in permanently but rather repeatedly. They induce continuous filling in and filling out of their prefabricated designs and thereby provide users with expectations of input information (a textual behavior). They continuously prod users—but don’t force them—to provide information and content using pre-structured designs that occur through a visual array of interactive fields and “qualitative affordances” such as likes, shares, and posts (Tarsa 22). Examples of repeatable, templated fields are the status update fields of Twitter (Figure 1) or Facebook (Figure 2). These template fields encourage users to fill in the template by posing a question—one that most likely becomes naturalized over time as users become adjusted to seeing the “What’s happening?” or “What’s on your mind?” repeatedly. The act of filling in these templates thus never ceases, and it becomes a type of habit, disposition, or hexis that is, following Hookway’s line of reasoning, subsequently forgotten.
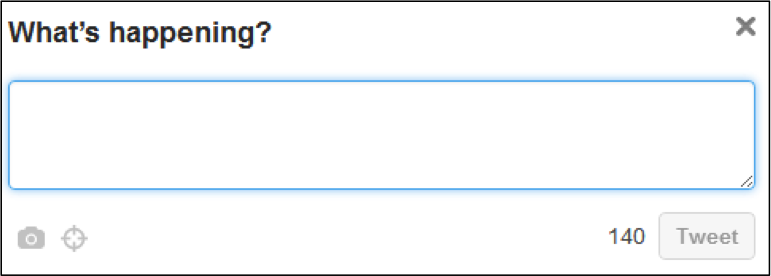
Figure 1. Status Update of Twitter on Laptop (9-6-2015)

Figure 2. Status Update of Facebook on Laptop (9-6-2015)
The repeatable and continuous logic of Web 2.0 templates provides numerous kinds of data that websites can gather from users and viewers, though some data are more user-specific than others. Because it’s directly written/produced by users, information entered through these templates builds profiles created by users themselves. User-produced information, such as checking in to locations, helps companies build detailed, targeted profiles about users in ways that general website analytics (i.e., page views, bounce rate, etc.) cannot. The information and profiles gleaned from Web 2.0 templates are designed for a user-created, updatable database, which can then be bought and sold.
Time-Space Compression
Web 2.0 templates afford time-space compression, or the idea that technology increases the speed of production, distribution, and circulation, especially in regards to the flow of capital (Harvey; Virilio). Time-space compression has been taken up by scholars to describe the way discursive information moves around the Internet.[7] Laurie Gries, in Still Life with Rhetoric, for example, draws on Tiziana Terranova to note:
From the perspective of ICT [information and communication technology] time…our messages seem much more everywhere at once and nowhere in particular. This is especially the case in network culture in which information spills from network to network both on the Internet and outernet and messages do not flow from a sender to receiver, but spread, mix, mutate, converge, diverge, and interact in a complex of multiplicity of communication channels. (31)
I would extend this description to Web 2.0 templates because, as widely engaged user interfaces, they warp understandings of time and space much like “information and communication technology” does to our sense of “duration” (30). Web 2.0 templates compress temporal relations through visual displays, often with a tendency to background temporal relations. As an illustrative example, Facebook’s template timeline infamously displays items in order of “importance” by default, with the emphasis here being that “important” is guided by proprietary algorithms. Other examples include instances when online comments on Reddit or Tumblr aren’t displayed linearly, leading to confusion about how to read online texts. Further, comments on blogs can be displayed literally close together and may be “read” as an accumulated, singular text—even when timestamps indicate extended passages of time have lapsed.
The ways that Web 2.0 templates compress time and space have major economic implications. Because information can be collected at rapid rates and in easily structured ways with Web 2.0 templates, corporations that run social media websites can turn information into sellable commodities more quickly and accumulate profits at increasing rates. Web 2.0 templates in this sense “…trend toward the general reduction of spatial barriers and speed-up” the circulation of information—text, pictures, and other discursive productions (Harvey 42). They shrink temporal relations and spatial configurations, which enables the accumulation of profit and value at ever-increasing rates.
Standardization of Collecting Information
The possibility of such high rates of information-generation is inextricably tied to the fact that Web 2.0 templates standardize user input. Without this standardization, the problem of extracting useful information from rapidly produced data would be intractable. Templates, in this sense, are an important part of the forces behind the spreading, mixing, mutation, convergence, divergence, and interaction of online messages and are part of what Collin Brooke calls the ecology of code, which is “…comprised not only of grammar but also of all those resources for the production of interfaces more broadly construed, including visual, aural, spatial, and textual elements…” (48). Web 2.0 templates inform users about what kind of information is supposed to be input. Input fields aren’t without surrounding context; and without that context, the information collected couldn’t be standardized. This standardization leads to easier monetization because information is more organized and structured. In this sense, Web 2.0 templates distribute and circulate rhetorical discourse because they function, to use an imperfect metaphor, as the veins or roads through which user-produced information travels. They enable the flow of information or block it. Through this standardization, these templates—and their programmers and designers—impose hegemonic communication practices on users. This hegemony manufactures a sense of expectation and decorum for writer-audience relationships.
Standardization makes funneling information collected from Web 2.0 templates easier because algorithms can be written to expect certain patterns of information. In this sense, these templates have in many ways mastered the rhetorical canon of (digital) memory, at least in terms of “information retrieval” (Eyman) or “persistence” (Brooke). Templates collect comments and status updates and record qualitative affordances. They then store this information on companies’ servers. In their function as the bridge by which user information becomes stored in databases and subsequently monetized, templates are a crucial rhetorical moment.
Encouraging Data Production
As discussed thus far in this article, templates encourage rather than force users to fill in templates with information through repeatability, time-space compression, and standardization. Companies can monetize information extracted from templates, suggesting that more information leads to more money. I believe that such financial drive for more user-produced data can be traced through the evolution of Web 2.0 designs. In this section, I will highlight an example of such an evolution (see fig. 3, 4, 5, and 6) with respect to Facebook’s template from 2005-2011. I specifically choose 2011 as the end point to highlight the changes that lead up to Facebook’s initial public offering. Note that these screenshots are recreations of the screenshots edited to highlight the interactive fields more effectively.

Figure 3. A Reconstruction of Facebook’s 2005 Homepage

Figure 4. A Reconstruction of Facebook’s 2007 Homepage
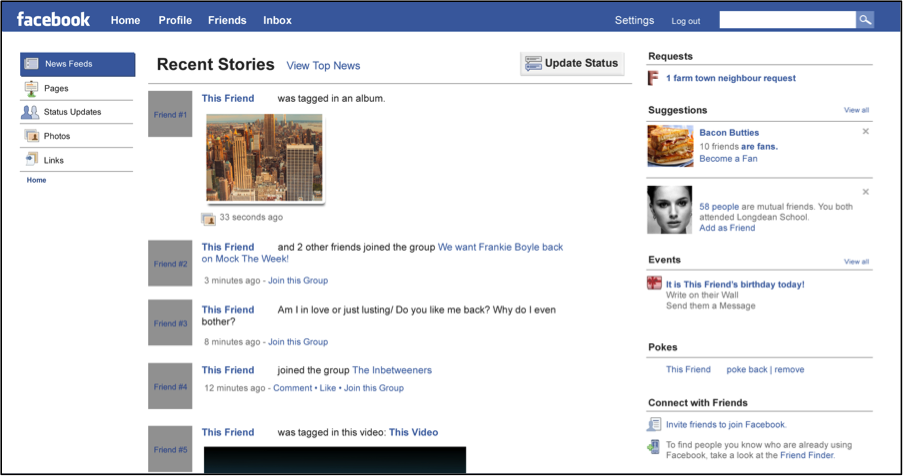
Figure 5. A Reconstruction of Facebook’s 2009 Homepage
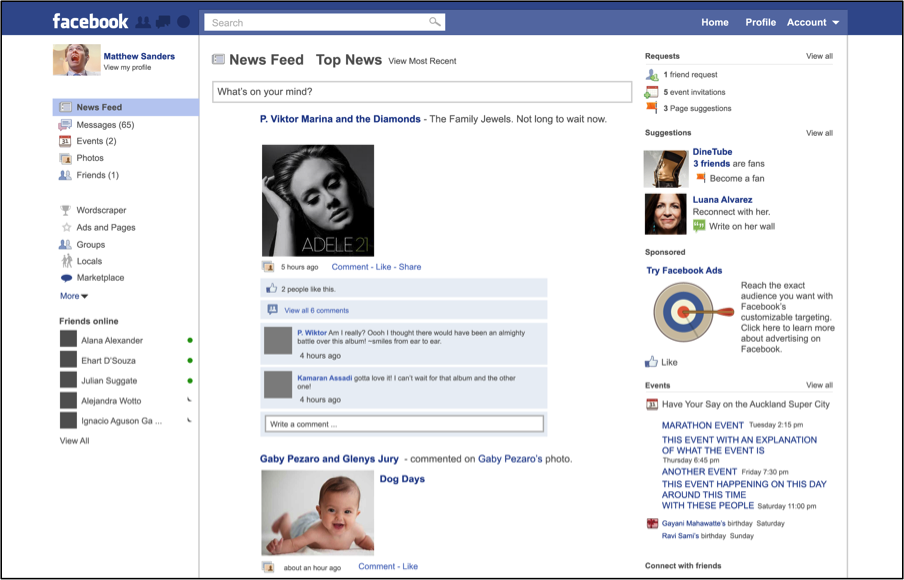
Figure 6. A Reconstruction of Facebook’s 2011 Homepage
These recreated screenshots illustrate the evolution of a repeatable and continuous online template, likely driven by an increasing ambition to monetize the site. The rise of interactive fields over this six-year span demonstrates how repeatability, time-space compression, and standardization convince users to revisit their Facebook profiles, which originally mimicked printed books on college campuses, to make sellable user data. User profiles that can be filled in only once have less sellable data than profiles designed to be filled in repeatedly. Facebook’s programmers thus redesigned the website’s templates so that users can fill in more fields and, subsequently, provide Facebook with more data.
Beginning in 2009, the rich site summary (RSS) newsfeed redesign, one that augmented time-space compression, shifted the site from a profile-oriented to a user-generated, content-oriented site. The origin of this shift could reflect many issues, such as a desire for more users, but the shift strongly signals a shift in decorum. Pictures and information were no longer encouraged as singular fill-in moments. Instead, the Facebook template invited users to provide a steady stream of information that could eventually, especially in light of Facebook’s public stock offering in the summer of 2011, be monetized. This evolution unequivocally indicates that monetization was a focus, because templates from 2007-2011 have advertisement spaces (see fig. 4, 5, and 6)—a notion that was reinforced in 2013 when Facebook introduced native advertising into users’ RSS feeds.
Redesigning templates or adding new affordances helps Facebook standardize user behavior so that the company can better identify the sentiment around posts and news articles. While this standardization makes user-to-user communication simpler and possibly more effective, it allows Facebook to better determine how users read and process information. This enables Facebook to use its templates to conceptualize audiences in targeted ways. An illustrative example of this targeting occurred in February of 2016 when Facebook rolled out its “reaction” system (see fig. 7).

Figure 7. Facebook’s Reactions as of February 2016 (on Laptop)
These reactions standardize select emotions from the audience. From a user perspective, they offer a wider range of expression than simply the “thumbs up” or “like” input. In this sense, these reactions increase the available means of persuasion. From Facebook’s perspective, these reactions give Facebook more insight into the behavior of their users for marketing and advertising purposes. With only a single “like” reaction, many users would opt not to react to some posts (e.g., a death or political statement they disagreed with) because of their hesitance to give the impression of liking it. By offering users this limited set of reactions (i.e., not a full complement of emojis), Facebook can entice users to react to a given post or news article, thus enabling the company to evaluate user response to that post or article. In terms of monetization, the analysis that can be run on these audience reactions is succinct enough for marketing and advertising purposes. The reactions, then, are expansive enough to increase the likelihood of active data production yet structured and limited enough to standardize the data collection practices necessary for monetization.
Templates as the Analytical Tool for Understanding Users
Because Web 2.0 templates act as this interface between users and database, they enable corporations to conceptualize audiences in quantitative ways. Philip M. Napoli calls this idea the “rationalization of audience understanding” (11). In Audience Evolution, Napoli describes “rationalization of audience understanding” in the following way:
…over time media industries' perceptions of their audience have become increasingly scientific and increasingly data-driven, with more impressionistic or instinctive approaches to audience understanding increasingly falling by the wayside. The days of…subjective assessments of what will succeed and what will fail have largely been replaced by a decision-making environment driven by a wide range of analyses of audience tastes, preferences, and historical behavioral patterns. (11)
Napoli describes a shift from understanding audience(s) in an instinctive manner to a quantitative, demographic approach that can be more easily commoditized. This data-driven paradigm of audience can be broken down into different categories of information. Users, customers, or readers can be defined by the information that companies gather about them.
The vast quantities of data made possible by Web 2.0 templates facilitate a “rationalization of audience” about users by encouraging companies (along with users themselves via qualitative affordances) to interrogate audiences in quantifiable, statistically-driven ways. As I have been arguing, Web 2.0 templates assist users in producing information repeatedly while simultaneously structuring that data for companies; in this way, they provide a demographic and quantifiable view of audiences for companies that want to monetize their users. From this perspective, the information users input into Web 2.0 templates is exceptionally powerful as it helps companies turn user data into commodities. Although there are other ways for companies to collect data (i.e., data production wherein companies track analytic activity on their sites), the data production enabled by Web 2.0 templates is much richer because users produce it themselves.
If users recognize that Internet companies need data to understand their behavior, then acts of inputting information into Web 2.0 templates become crucial rhetorical situations. Recognizing such situations positions users as information workers who provide a valuable service yet also have the power to impact databases.[8] But in order to contend with the monetization of user content, we need to develop ways to fill in Web 2.0 templates strategically.
A Rhetorical Practice of Active Data Production
If we view filling in Web 2.0 templates as monetary transactions—an economic rhetorical situation—we can more effectively navigate the commodification of our online activity and labor. Let me be clear: I am not advocating solely for resistance but for users to participate and resist when it’s strategically useful for their purposes. Strategic use of Web 2.0 templates can be economically as well as socially beneficial. For instance, Rita Raley, in “Dataveillance and Countervailance,” writes:
In order to receive customized rather than generalized services, one of course has to provide information to corporations and institutions so that they might better support our preferences, profiles, and favorites. After all, this line of thinking holds, do we not want a personalized Internet that adapts to our individual tastes, habits, and preferences? (125)
While Raley goes on to be more critical of data collection and surveillance, her question illuminates an important tension: there are benefits/drawbacks to having one’s information collected (i.e., participating) and benefits/drawbacks to resisting participation in online culture. I will offer one rhetorical practice to begin navigating both resistance and participation, though additional methods and rhetorical practices are needed to explore more fully the relationship between user information and economic online activity.
The strategy I endorse here is a rhetorical practice of active data production. This practice foregrounds uncompensated online writing and activity, a form of unpaid labor, which occurs when filling in Web 2.0 templates.[9] In other words, users view their discursive acts as products of the website’s host. For example, when I send out a tweet, that’s a product Twitter can sell (interested individuals can purchase a large number of tweets). Even if my tweet is interesting, gets retweeted, and gives me more followers, that tweet is always-already an interaction between customer/product (user) and company (Twitter).
A rhetorical practice of active data production, as a careful and considered use of filling in Web 2.0 templates, shifts our view of online activity from personal and/or community-based to corporately-driven. This strategy acknowledges that the information users produce is imbricated within a knowledge economy while recognizing the practicality of using Web 2.0 templates for communication. Thus, even if all of our input can be monetized through analysis of metadata and Web 2.0 template collection, we need not abandon using Web 2.0 websites (further, I don’t think this is feasible). Rather, manipulating our use of Web 2.0 templates in ways that are beneficial to users—monetarily, socially, and politically—is a more profitable route. The conundrum comes down to what is “beneficial?” After all, companies provide a service for users, often times a convenient—if exploitive—one. To ascertain what is beneficial, users need to see and understand the way their data is collected and stored. We need to both unmask the ways templates turn input information into sellable data and manipulate data so that it suits our desired purposes in a given moment (resistance and participation).
A rhetorical practice of active data production amounts to a heightened user awareness that sees online discursive production as monetized labor. The text and images entered into templates acquire a monetary value because they are recorded and stored in a database and have some sort of exchange value for companies. Although users are circumscribed by larger cultural, online forces, in the scope my argument here, users control the input information through their writing and other discursive habits. In this sense, users have some power to combat invisible information asymmetry because they are the information source and site of resistance. This means that users, when engaging with this practice of active data production, have a particularly persuasive role because they view themselves as part of a demographic (i.e., Napoli’s “rationalization of audience understanding”) to be measured and evaluated by a website’s designers and managers. Upon such realization, they may be able to better control the monetization of their user data, especially if they view the interaction between themselves and their particular Web 2.0 template as rhetorical and a point at which information-extraction can be controlled.
Strategies for a Rhetorical Practice of Active Data Production
In this section, I want to introduce three strategies for the rhetorical practice of active data production. The first strategy encourages developing habits and techniques that allow us to see relationships between what we input into Web 2.0 templates and the way that information is collected and stored. In general terms, this involves keeping track of one’s own data, making records of one’s personal activity, and keeping track of the changes websites make in response to user input. Admittedly, this level of detail and tracking is not practical in terms of time or effort for most users. For this reason, a useful and concrete technique is to download information, when possible, so that we can access and analyze our activity. Three widely used Web 2.0 websites—Facebook, Twitter, and Instagram—allow users to download their activity. Downloading information moves us from the aesthetically-pleasing view of Web 2.0 templates to the database version of them. Such engagement enables users to see how data are stored—literally see it in spreadsheets, zipped files, or, more generally, as semi-structured data (see fig. 8)—and, therefore, directly see Web 2.0 templates as recording devices designated for monetary purposes. Viewing information in columns and rows can move us as users toward a rhetorical understanding of our discursive production as structurally administrative and economic. If users see their discursive productions within the context of structured databases, they may be better able to understand their information in terms of a product that can be bought and sold.
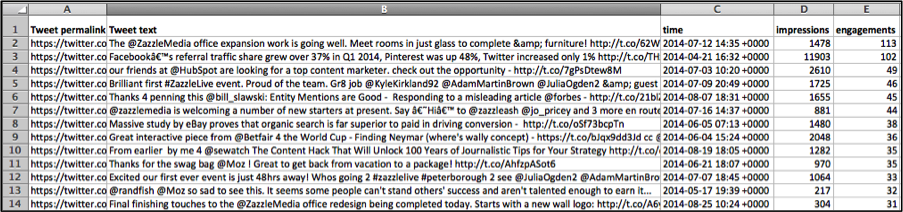
Figure 8. Sample Image of Downloaded Tweets from Twitter
The second strategy for active data production is for users to produce their online discursive activity outside of Web 2.0 templates. Before filling in Web 2.0 templates, users should write and compose in spaces not connected to the Internet. This habit is important because it asks users to produce information without running the risk of templates collecting the data via scripting processes that run in the background of interactive Web 2.0 templates (one of my sources, a former Facebook employee, stated that Facebook constantly collects typed data even when users don’t enter the information). Writing status updates in word documents, composing tweets out by hand, or editing images outside of Instagram or Snapchat filters is an important habit to combat the immediate processing, collection, and distribution of user information by Web 2.0 templates and their algorithms.
A third strategy of active data production involves strategically filling in Web 2.0 templates with a priority on the possible commodification of a user’s discursive production (i.e., alphabetic text, images, and qualitative affordances). Doing so requires an individual user to weigh the costs and benefits of personal data production. In this regard, an effective rhetorical practice of active data production might encourage filling in templates with information that may be either deliberately inaccurate or misleading, as opposed to accurate. Doing so calls for users to intentionally resist and challenge commodification of data when they deem it appropriate. Such resistance via deliberately misleading information parallels what Finn Brunton and Helen Nissenbaum call obfuscation or “…the deliberate addition of ambiguous, confusing, or misleading information to interfere with surveillance and data collection” (1). While they explore obfuscation within the scope of privacy and social/political protest, I reorient the term to focus on labor, monetization, and data commodification. In other words, my use of obfuscation here is designed to provide rhetors with an actionable view of the monetary relationship between data collection practices of corporate websites and information produced by users.
The acknowledgement that writing in a Web 2.0 environment results in possible commodification aligns with Brunton and Nissenbaum’s idea that there exists a “necessary visibility” in which the “obfuscator is already exposed to some degree” (85). Users implementing a rhetorical practice of active data production understand that although users may become visible (to companies) when producing monetized data, this visibility also acts as a source of resistance to their data being used in undesirable ways. Users may purposefully fill in templates with information that is ambiguous, confusing, or misleading when filling out Web 2.0 templates to address “information asymmetry, which occurs when data about us are collected in circumstances we may not understand, for purposes we may not understand, and are used in ways we may not understand” (2-3). In the case of Web 2.0 environments, users produce information for other users, which is co-opted by companies that seek to buy and sell this information. Thus, deliberately filling in templates with inaccurate information may give users a better sense of agency and, perhaps, allow users to break corporate filters. An example of this strategy includes filling in birthdates incorrectly to see targeted advertising outside one’s typical age demographic. Other examples include using certain Twitter hashtags to emerge from filter bubbles or create accounts with false names to engage other Facebook or Twitter users in unexpected ways.
Templates may—and probably at times should—still be filled in with accurate information. Filling in Web 2.0 templates accurately can sometimes offer users useful information (from the perspective of the user). When purchasing items on Amazon or using Google, for instance, having relevant suggestions based on user-produced information may sometimes be helpful in terms of buying products or finding directions. Other examples may include creating accurate peer or professional networks that Internet companies can help expand (e.g., LinkedIn and Academia.edu). Filling in templates accurately may also be useful if you are a businessperson or an academic who wants to monetize your research or develop a professional brand. Still, to gain a better sense of control in Web 2.0 environments, users ought to resist desires to write quickly and ambiently, instead writing deliberately and slowly.[10]
False Accounts: A Practice for Monitoring Active and Inactive Data Production
Up to this point, I have not addressed inactive data production. By inactive data production, I mean the act of producing data that is not entered through templates. Companies track inactive data through cookies, trackers, and widgets. Examples of collected inactive data include page views, time spent on websites, IP address location, and other web-browsing habits that can be quantified. I believe the three previous strategies discussed can be applied, albeit indirectly, to this type of data production because they involve monitoring one’s own habits as a form of monetizable labor. The example below directly addresses obfuscation in the context of templates and inactive data production: setting up false accounts (i.e., sock-puppets) and filling in the templates of this account with information that is different from one’s personal accounts. Comparing and contrasting the differences in these accounts can provide insight into the way active and inactive data production changes our perceptions (literally and metaphorically) of the Internet. As an example, I perform a comparison between my personal Facebook profile and a false account I created for a 22-year-old female named Harry Poderick (input data was 22 years old and a female). I built this sock-puppet account using an email account associated with the University of Illinois at Urbana Champaign (i.e., “@illinois.edu”).
In my personal Facebook profile, I have filled out my birthdate as January 1, 1950 (this is not my birthdate). My false birthdate on Facebook often leads to advertisements that do not (yet) apply to me. For instance, I frequently receive advertisements from the AARP. I also receive advertisements directed at me using the location of my IP address (see fig. 9).

Figure 9. Advertisement for a Health Alliance Medicare, Which Has a Branch in the Neighboring Town of Urbana, IL
Compare this Health Alliance advertisement, which relies on both active data production (my input birthdate) and inactive data production (my IP address in Champaign, IL), with the initial suggestion from my sock-puppet account shown in Figure 10. The latter image, one of the women’s volleyball team[11] at the University of Illinois at Urbana-Champaign (UIUC), appeared in the advertising bar of the sock-puppet account. While either the IP address (in the Champaign-Urbana area) or the email address may account for UIUC banners, the targeted page of a female college team is most likely because of active and inactive data production.

Figure 10. Suggestions to “Like” the Women’s Illini Volleyball Team
Both images (Figures 9 and 10) emerge in part from inactive data production (IP address). Importantly, Figure 10 came from a clean browser history, and no advertisements appeared.[12] However, this example clearly demonstrates that the difference between my personal account advertising (i.e., fig. 9) and the sock-puppet account advertising (i.e., fig. 10) is heavily mediated by actively produced data. In my personal online activities, I’ve never seen an advertisement for UIUC sports. In creating an account for a female with a UIUC email, however, I was immediately greeted with a female UIUC sports team. Filling in the templates of the sock-puppet account produced a targeted suggestion. More broadly, in the sock-puppet account, there were no commercial advertisements yet. Harry Poderick, the 22-year-old female avatar, has no friends and no trail of actively produced data. Facebook as a company has yet to turn Harry Poderick’s (my) data into commodities that can be sold back to her or to her connections. Facebook can only target Harry Poderick’s preferences from my email address, IP address, and the gender/age I entered. This example, along with the other aspects of a rhetorical practice of active data production described earlier, provides users with ways to rethink and develop an increased awareness of the monetization and commodification of their data. By comparing differences between these accounts, we can take deliberate steps to learn how inputting information alters the display of templates. Rhetorical practices of active and inactive data production can subsequently assist users in developing habits for conscious, rhetorical agency in the hyper-mediated, commercialized context of Web 2.0.
Agency on the Internet
One of the broader implications of a rhetorical practice of active data production is its relationship to agency in the context of an information/attention economy and the Internet. I have identified a rhetorical problem (passively allowing companies to collect user data in a non-rhetorical manner) and a possible solution (a rhetorical practice of active data production). In doing so, I have endeavored to show that users can acquire certain levels of agency—the ability to make choices and effect change with those choices—by recognizing their own habits of active data production and by strategically deciding what information to input into Web 2.0 templates. A rhetorical practice of active data production on the Internet encourages users to see their online activity as labor, which, in turn, and if desired, enables them take action to resist the commodification of their data. As Christian Fuchs puts it, “…it is difficult to see that corporate social media use is a form of labour, value generation, and exploitation because corporate social media’s commodity form…makes the commodity form invisible and hard to grasp and understand for users…” (378). This article is meant to begin the process for taking rhetorical action via active data production in a world filled with overlooked interfaces and metaphors that obscure users’ relationships to their technologies.
As we consider active data production, an important part of agency here is recognizing the disjunction between technologies and the language that surrounds them. The input information of Web 2.0 templates is stored in massive physical databases, but rhetoric surrounding those databases assumes a disembodied, ephemeral nature (“the cloud”). Our language, especially the kind of language derived from corporate marketing and advertisers, mystifies physical-technological relationships. It’s easy to forget that the Internet is built out of things and by companies. We use the term “cloud” for servers that crowd basements and occupy large tracts of land; what if we called it the “swamp”? Algorithms don’t think.[13] What if we continue to investigate the people doing the programming, inquiring as to their motivations and making those motivations public? When we denaturalize our technology and our role in producing monetizable data, we can begin to see the direct relationship between discursive production and the Internet economy. Denaturalizing Web 2.0 templates through active data production is but one step. We need more rhetorical practices to unearth and wade through the swamp.
Acknowledgements: I would like to thank Laurie Gries for her excellent and generous editorial assistance, the two anonymous reviewers, and Jon Stone for reading an early draft of this article.
[1] The exigence here is that companies aim to monetize user-produced information. While other user-to-user exigencies may exist, this exigency remains constant throughout Web 2.0 template interactions.
[2] It’s important to note that by focusing on the economic exchange of IPI templates, I background the user-to-user relationships facilitated by such templates.
[3] The term is also historical: Web 2.0 was meant to distinguish the successful Internet businesses from the ones that failed to survive the burst of the “dot com” bubble in the late 1990s.
[4] For an extended discussion of the role algorithms play, see Frank Pasquale’s The Black Box Society.
[5] N. Katherine Hayles tangentially touches on interface in How We Think. Her discussion of the way readers, especially students, process digital information (55-83) is an invaluable discussion for informing our understanding of the ways that users need to read and write with IPI templates.
[6] It’s important to note here that some IPI templates are open to hacking, although that topic is outside the scope of this article.
[7] For instance, Ridolfo and DeVoss have taken up and reoriented this concept as it pertains to delivery through the concept of rhetorical velocity.
[8] This recognition reflects Alan Liu’s oft-quoted idea that “I went to sleep one day a cultural critic and woke the next metamorphosed into a data processor” (4). Most users don’t actively see themselves as information workers for their various template providers. We are aware from time to time or in the background of our daily activities. I want to foreground our roles as information workers because it helps to better recognize our roles in the online economy as information producers.
[9] I would not apply this practice to paid online writers or content producers because they have different rhetorical strategies for understanding their activity.
[10] I echo here John Duffy’s thoughtful idea that we need to inculcate deliberate habits as writers.
[11] There is no men’s team at UIUC.
[12] There was a suggestion that Harry Poderick follow Mark Zuckerberg on Facebook
[13] I echo Jim Brown’s and Annette Vee’s thoughts in Eric Detwiler’s November 10, 2015 episode of Rhetoricity. In the episode, “Rhetoric’s Algorithms,” Brown and Vee discuss the way that algorithms must be authored—that is, the rules of algorithms must be “authored and written” by “someone or something” (10:00-11:30).
Arola, Kristin L. "The Design of Web 2.0: The Rise of the Template, The Fall of Design." Computers and Composition vol. 27, no. 1 (2010): pp. 4-14.
Brooke, Collin G. Lingua Fracta: Toward A Rhetoric of New Media. Edited by Gail E. Hawisher and Cynthia Selfe. Cresskill, NJ: Hampton Press, 2009. Print.
Brunton, Finn and Helen Nissenbaum. Obfuscation: A User's Guide for Privacy and Protest. Cambridge: MIT P, 2015. Print.
Detweiler, Eric. "Rhetoric's Algorithms: Jim Brown and Annette Vee." Audio Podcast. Rhetoricity. 10 November 2015. http://rhetoricity.libsyn.com/2015/11.
Duffy, John. “Ethical Dispositions: A Discourse for Rhetoric and Composition.” JAC vol. 34, no. 1-2 (2014): pp. 209–37. Print.
Eyman, Douglas. Digital Rhetoric: Theory, Method, Practice. Ann Arbor: U of Michigan P, 2015. Print.
Fuchs, Christian. Culture and Economy in the Age of Social Media. New York: Routledge, 2015. Print.
Gallagher, John. "The Rhetorical Template." Computers and Composition vol. 35, no. 1 (2015): pp. 1-11.
Gries, Laurie. Still Life With Rhetoric: A New Materialist Approach for Visual Rhetorics. Logan: Utah State UP, 2015. Print.
Harvey, David. The Condition of Postmodernity: An Enquiry into the Origins of Cultural Change. London: Basil Blackwell, 1989. Print.
Hayles, Katherine. how we think: Digital Media and Contemporary Technogenesis. Chicago: U of Chicago P, 2012. Print.
Holmes, Steve. "Rhetorical Allegorithms in Bitcoin." enculturation vol. 18 (2014). Web. 18 September 2015. enculturation.net/rhetoricalallegorithms.
Hookway, Branden. Interface. Cambridge: MIT P, 2014. Print.
Liu, Alan. The Laws of Cool: Knowledge Work and the Culture of Information. Chicago: U of Chicago P, 2004. Print.
Napoli, Philip M. Audience Evolution: New Technologies and the Transformation of Media Audiences. New York: Columbia U P, 2011. Print.
O'Reilly, Tim. "What is Web 2.0: Design Patterns and Business Models for the Next Generation of Software." Communications & Strategies vol. 65, no. 1, p. 17-37.
Pasquale, Frank. The Black Box Society: The Secret Algorithms That Control Money and
Information. Cambridge: Harvard UP, 2015. Print.
Ridolfo, Jim and Danielle Nicole Devoss. "Composing for Recomposition: Rhetorical Velocity and Delivery." Kairos: A Journal of Rhetoric, Technology, and Pedagogy vol. 13, no. 2 (2009). www.technorhetoric.net/13.2/topoi/ridolfo_devoss/.
Raley, Rita. "Dataveillance and Countersurveillance." Raw Data is an Oxymoron. Edited by Lisa Gitelman. MIT P, 2013. 121-45. Print.
Tarsa, Rebecca. "Upvoting the Exordium: Literacy Practices of the Digital Interface." College English vol. 78, no. 1 (2015): pp. 12-33. Print.
Virlio, Paul. Speed and Politics: An Essay on Dromology. 2nd edition. New York: Semiotext(e), 2006. Print.